1. What is logistic regression?
2. What is the syntax for logistic regression?
Library: sklearn.linear_model.LogisticRegression
Define model: lr = LogisticRegression()
Fit model: model = lr.fit(x, y)
Predictions: pred = model.predict_proba(test)
3. How do you split the data in train / test?
Syntax: X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
4. What is decision tree?
5. What is the syntax for decision tree classifier?
Define model: dtc = DecisionTreeClassifier()
Fit model: model = dtc.fit(x, y)
Predictions: pred = model.predict_proba(test)
6. What is random forest?
7. What is the syntax for random forest classifier?
Define model: rfc = RandomForestClassifier()
Fit model: model = rfc.fit(x, y)
Predictions: pred = model.predict_proba(test)
8. What is gradient boosting?
9. What is the syntax for gradient boosting classifier?
Define model: gbc = GradientBoostingClassifier()
Fit model: model = gbc.fit(x, y)
Predictions: pred = model.predict_proba(test)
10. What is SVM?
11. What is the difference between KNN and KMeans?
KNN:
Classifies new data points accordingly to the k number or the closest data points
KMeans:
Unsupervised clustering algorithm
Groups data into k number of clusters.
12. How do you treat missing values?
Drop rows having missing values
DataFrame.dropna(axis=0, how=’any’, inplace=True)
Drop columns
Replace missing values with zero / mean
df[‘income’] = df[‘income’].fillna((df[‘income’].mean()))
13. How do you treat outliers?
Q3 = df[‘income’].quantile(0.75)
IQR = Q3 — Q1
df = df[(df[‘income’] >= (Q1–1.5 * IQR)) & (df[‘income’] <= (Q3 + 1.5 * IQR))]
14. What is bias / variance trade off?
Definition
The Bias-Variance Trade off is relevant for supervised machine learning, specifically for predictive modelling. It’s a way to diagnose the performance of an algorithm by breaking down its prediction error.
Error from Bias
Bias is the difference between your model’s expected predictions and the true values.
This is known as under-fitting.
Does not improve with collecting more data points.
Error from Variance
This is known as over-fitting.
Improves with collecting more data points.
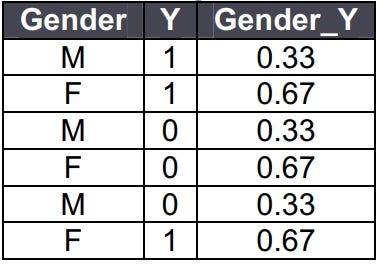
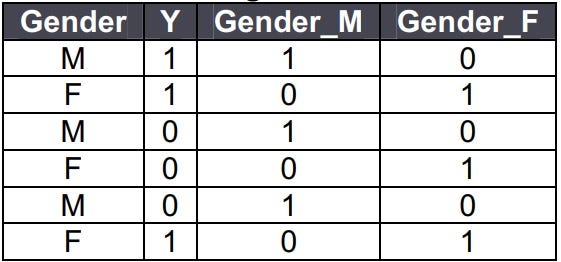
15. How do you treat categorical variables?
Replace categorical variables with the average of target for each category
Comments
Post a Comment